Eles aí estão, quentinhos...
Acabei de pôr à prova o meu programa, e para isso durante todo este fim-de-semana usei o computador Gazela no laboratório de projectos da Universidade, mais o computador Girafa. O Gazela, uma vez que tem um processador rápido (AMD Athlon 1800+) com 768 MB de RAM era o candidato óbvio para correr o cliente, devido a ficar encarregue de fazer "todo o trabalho" de desenvolvimentos dos indivíduos, a sua avaliação e competição. O servidor, ao contrário do que é usual, era somente passivo nesta questão, uma vez que o seu trabalho era simplesmente receber as diferenças do último vector população e actualizá-lo, verificando se entretanto não teria convergido. Com apenas 192 MB de RAM, também não era preciso muito, apesar do servidor de JSP Tomcat ser um bocado pesado, já que, sendo uma aplicação concebida em JAVA, que é um devorador de recursos em qualquer máquina.
Mas o que importa é que, depois de uma série de contratempos e de ter tentado pôr o meu trabalho a usar a Internet "a sério", com o servidor no meu servidor/gateway Linux caseiro a fazer de servidor, e uma máquina qualquer na Universidade a fazer de cliente, podia ter uma aproximação mais próxima da realidade, se é que alguma vez o meu trabalho venha a ser usado na Internet, tenho esperanças de que sim :).
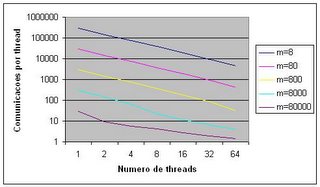
Enfim, vamos mas ao que interessa, aqui estão os gráficos das experiências que fiz durante o fim de semana. Segui quase à risca as mesmas condições do artigo Referência fundamental para o projecto : Lobo F. G., Lima C. F. & Mártires H. (2004). An Architecture for Massive Parallelization of the Compact Genetic Algorithm. (PDF) na página 8, e experimentei combinações de valores de m (máximo de execuções da função de fitness entre cada comunicação com o servidor) no intervalo {8,80,800,8000,80000} com números de threads (equivalente a processadores) no intervalo {1,2,4,8,16,32,64}. O artigo tem gráficos que vão até 1028, mas como a partir de 64, os gastos de RAM dispendida para a criação de threads são enormes, decidi deixá-los para outra ocasião. Os resultados apresentados resultam da média calculada da execução de 6 experiências para todas as combinações possíveis aos pares entre os valores dos dois intervalos. Excepto para m=8, em que a execução do cliente é extremamente demorada para poder obter um número de experiências em tempo útil. Para ter uma ideia do que tou a falar, a execução do cliente com m=8 mesmo com 64 threads precisou de 7550 segundos (um pouco mais de 2 horas) para se poder completar. Para este caso, apenas procedi (por enquanto) apenas a uma 1 execução para cada valor de threads possíveis no intervalo indicado.
Aqui estão os gráficos, elaborados com a ajuda do Excel, precedido do respectivo gráfico do artigo supracitado, cujos resultados pretende reproduzir:
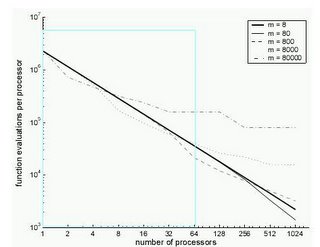


Não pretendo ficar por aqui, pretendo pelo menos completar a metade direita do gráfico que ficou de fora assinalada pelo quadrado colorido, se tiver a gana, mas também o hardware para poder fazer isso. Fiquem a aguardar as notícias dos próximos capítulos :)
P.S.:Estes não são os gráficos definitivos que pretendo colocar no relatório.
Mas o que importa é que, depois de uma série de contratempos e de ter tentado pôr o meu trabalho a usar a Internet "a sério", com o servidor no meu servidor/gateway Linux caseiro a fazer de servidor, e uma máquina qualquer na Universidade a fazer de cliente, podia ter uma aproximação mais próxima da realidade, se é que alguma vez o meu trabalho venha a ser usado na Internet, tenho esperanças de que sim :).
Enfim, vamos mas ao que interessa, aqui estão os gráficos das experiências que fiz durante o fim de semana. Segui quase à risca as mesmas condições do artigo Referência fundamental para o projecto : Lobo F. G., Lima C. F. & Mártires H. (2004). An Architecture for Massive Parallelization of the Compact Genetic Algorithm. (PDF) na página 8, e experimentei combinações de valores de m (máximo de execuções da função de fitness entre cada comunicação com o servidor) no intervalo {8,80,800,8000,80000} com números de threads (equivalente a processadores) no intervalo {1,2,4,8,16,32,64}. O artigo tem gráficos que vão até 1028, mas como a partir de 64, os gastos de RAM dispendida para a criação de threads são enormes, decidi deixá-los para outra ocasião. Os resultados apresentados resultam da média calculada da execução de 6 experiências para todas as combinações possíveis aos pares entre os valores dos dois intervalos. Excepto para m=8, em que a execução do cliente é extremamente demorada para poder obter um número de experiências em tempo útil. Para ter uma ideia do que tou a falar, a execução do cliente com m=8 mesmo com 64 threads precisou de 7550 segundos (um pouco mais de 2 horas) para se poder completar. Para este caso, apenas procedi (por enquanto) apenas a uma 1 execução para cada valor de threads possíveis no intervalo indicado.
Aqui estão os gráficos, elaborados com a ajuda do Excel, precedido do respectivo gráfico do artigo supracitado, cujos resultados pretende reproduzir:
NÚMEROS DE CÁLCULOS DE FITNESS POR THREAD


COMUNICAÇÕES POR THREAD


Não pretendo ficar por aqui, pretendo pelo menos completar a metade direita do gráfico que ficou de fora assinalada pelo quadrado colorido, se tiver a gana, mas também o hardware para poder fazer isso. Fiquem a aguardar as notícias dos próximos capítulos :)
P.S.:Estes não são os gráficos definitivos que pretendo colocar no relatório.
posted by pescadordigital at 00:50
![]()


0 Comments:
Enviar um comentário
<< Home